用Python做单变量数据集的异常点分析
2014年6月12日星期四
import numpy as np
import pandas as pd
df = pd.read_csv("farequote.csv")
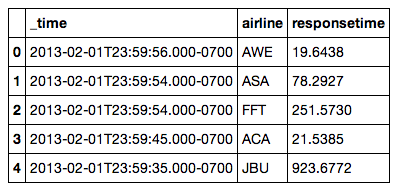
array(['AAL', 'ACA', 'AMX', 'ASA', 'AWE', 'BAW', 'DAL', 'EGF', 'FFT',
'JAL', 'JBU', 'JZA', 'KLM', 'NKS', 'SWA', 'SWR', 'TRS', 'UAL', 'VRD'],
dtype='|S3')
dd = df.query('airline=="KLM"') ## 得到法航的数据
dd.responsetime.describe()
count 1724.000000 mean 1500.613766 std 100.085320 min 1209.766800 25% 1434.084625 50% 1499.135000 75% 1567.831025 max 1818.774100 Name: responsetime, dtype: float64
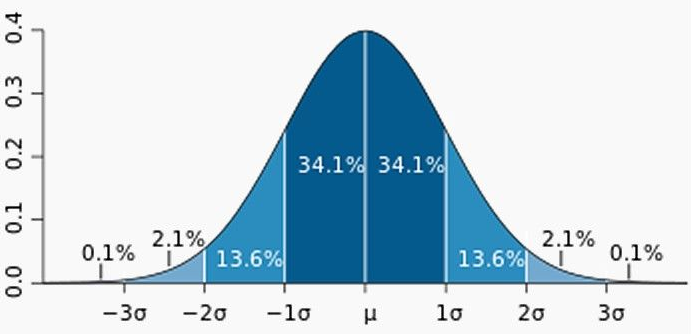
基于标准差得异常检测
- 95.449974面积在平均数左右两个标准差的范围内
- 99.730020%的面积在平均数左右三个标准差的范围内
- 99.993666的面积在平均数左右三个标准差的范围内
def a1(dataframe, threshold=.95):
d = dataframe['responsetime']
dataframe['isAnomaly'] = d > d.quantile(threshold)
return dataframe
print a1(dd)
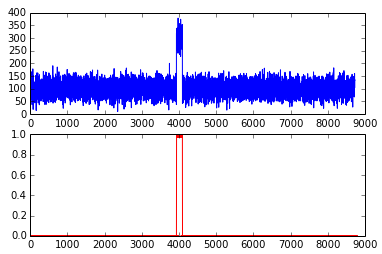
_time airline responsetime isAnomaly 20 2013-02-01T23:57:59.000-0700 KLM 1481.4945 False 76 2013-02-01T23:52:34.000-0700 KLM 1400.9050 False 124 2013-02-01T23:47:10.000-0700 KLM 1501.4313 False 203 2013-02-01T23:39:08.000-0700 KLM 1278.9509 False 281 2013-02-01T23:32:27.000-0700 KLM 1386.4157 False 336 2013-02-01T23:26:09.000-0700 KLM 1629.9589 False 364 2013-02-01T23:23:52.000-0700 KLM 1482.5900 False 448 2013-02-01T23:16:08.000-0700 KLM 1553.4988 False 511 2013-02-01T23:10:39.000-0700 KLM 1555.1894 False 516 2013-02-01T23:10:08.000-0700 KLM 1720.7862 True 553 2013-02-01T23:06:29.000-0700 KLM 1306.6489 False 593 2013-02-01T23:03:03.000-0700 KLM 1481.7081 False 609 2013-02-01T23:01:29.000-0700 KLM 1521.0253 False 666 2013-02-01T22:56:04.000-0700 KLM 1675.2222 True ... ... ... ...
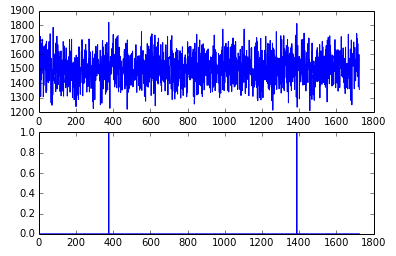
- 方法a1定义了一个异常检测的函数
- dataframe['responsetime']等价于dataframe.responsetime,该操作取出responsetime这一列的值
- d.quantile(threshold)用正态分布假定返回位于95%的点的值,大于该值得点都落在正态分布95%之外
- d > d.quantile(threshold)是一个数组操作,返回的新数组是responsetime和threshold的比较结果,[False,False,True,... ... False]
- 然后通过dataframe的赋值操作增加一个新的列,标记所有的异常点。
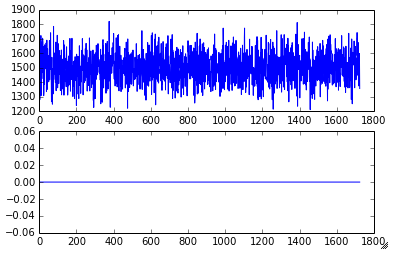
import matplotlib.pyplot as plt da = a1(dd) fig = plt.figure() ax1 = fig.add_subplot(2, 1, 1) ax2 = fig.add_subplot(2, 1, 2) ax1.plot(da['responsetime']) ax2.plot(da['isAnomaly'])
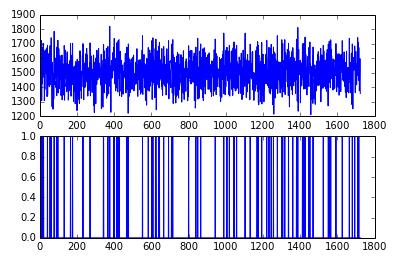
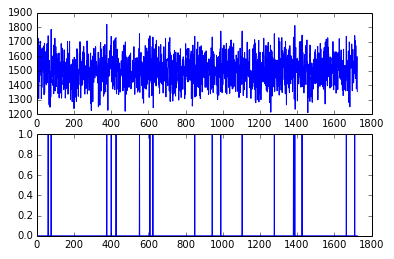
基于ZSCORE的异常检测
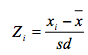
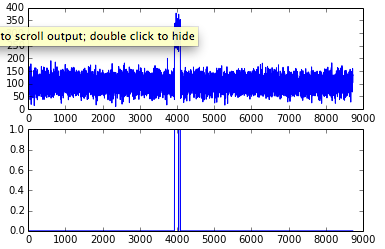
def a2(dataframe, threshold=3.5):
d = dataframe['responsetime']
zscore = (d - d.mean())/d.std()
dataframe['isAnomaly'] = zscore.abs() > threshold
return dataframe
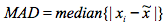
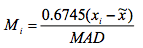
def a3(dataframe, threshold=3.5):
dd = dataframe['responsetime']
MAD = (dd - dd.median()).abs().median()
zscore = ((dd - dd.median())* 0.6475 /MAD).abs()
dataframe['isAnomaly'] = zscore > threshold
return dataframe
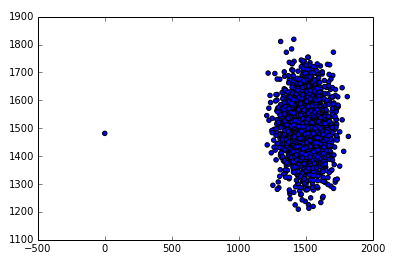
基于KMEAN聚集的异常检测
preresponse = 0
newcol = []
newcol.append(0)
for index, row in dd.iterrows():
if preresponse != 0:
newcol.append(preresponse)
preresponse = row.responsetime
dd["t0"] = newcol
plt.scatter(dd.t0,dd.responsetime)
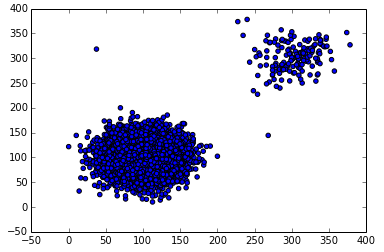
def a4(dataframe, threshold = .9):
## add one dimention of previous response
preresponse = 0
newcol = []
newcol.append(0)
for index, row in dataframe.iterrows():
if preresponse != 0:
newcol.append(preresponse)
preresponse = row.responsetime
dataframe["t0"] = newcol
## remove first row as there is no previous event for time
dd = dataframe.drop(dataframe.head(1).index)
clf = cluster.KMeans(n_clusters=2)
X=np.array(dd[['responsetime','t0']])
cls = clf.fit_predict(X)
freq = itemfreq(cls)
(A,B) = (freq[0,1],freq[1,1])
t = abs(A-B)/max(A,B)
if t > threshold :
## "Anomaly Detected!"
index = freq[0,0]
if A > B :
index = freq[1,0]
dd['isAnomaly'] = (cls == index)
else :
## "No Anomaly Point"
dd['isAnomaly'] = False
return dd
clf = cluster.KMeans(n_clusters=2) X=np.array(dd[['responsetime','t0']]) cls = clf.fit_predict(X)
freq = itemfreq(cls)
总结
标签: Data, Data Analysis, Python
这些年,我穿过的那些队服
















标签: soccer
使用Python抓取欧洲足球联赛数据
背景
Web Scraping
- 数据的采集和获取
- 数据的清洗,抽取,变形和装载
- 数据的分析,探索和预测
- 数据的展现
Web Scraping 注意事项
- 阅读网站有关数据的条款和约束条件,搞清楚数据的拥有权和使用限制
- 友好而礼貌,使用计算机发送请求的速度飞人类阅读可比,不要发送非常密集的大量请求以免造成服务器压力过大
- 因为网站经常会调整网页的结构,所以你之前写的Scraping代码,并不总是能够工作,可能需要经常调整
- 因为从网站抓取的数据可能存在不一致的情况,所以很有可能需要手工调整
Python Web Scraping 相关的库
- BeautifulSoup http://www.crummy.com/software/BeautifulSoup/
- Scrapy http://scrapy.org/
- webscraping https://code.google.com/p/webscraping/
Web Scraping 代码
pip install beautifulsoup4

from urllib2 import urlopen import urlparse import bs4 BASE_URL = "http://soccerdata.sports.qq.com" PLAYER_LIST_QUERY = "/playerSearch.aspx?lega=%s&pn=%d" league = ['epl','seri','bund','liga','fran','scot','holl','belg'] page_number_limit = 100 player_fields = ['league_cn','img','name_cn','name','team','age','position_cn','nation','birth','query','id','teamid','league']
def get_players(baseurl):
html = urlopen(baseurl).read()
soup = bs4.BeautifulSoup(html, "lxml")
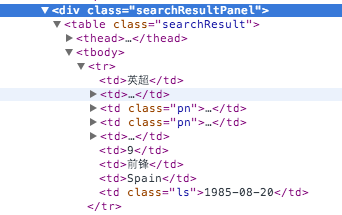
players = [ dd for dd in soup.select('.searchResult tr') if dd.contents[1].name != 'th']
result = []
for player in players:
record = []
link = ''
query = []
for item in player.contents:
if type(item) is bs4.element.Tag:
if not item.string and item.img:
record.append(item.img['src'])
else :
record.append(item.string and item.string.strip() or 'na')
try:
o = urlparse.urlparse(item.a['href']).query
if len(link) == 0:
link = o
query = dict([(k,v[0]) for k,v in urlparse.parse_qs(o).items()])
except:
pass
if len(record) != 10:
for i in range(0, 10 - len(record)):
record.append('na')
record.append(unicode(link,'utf-8'))
record.append(unicode(query["id"],'utf-8'))
record.append(unicode(query["teamid"],'utf-8'))
record.append(unicode(query["lega"],'utf-8'))
result.append(record)
return result
result = []
for url in [ BASE_URL + PLAYER_LIST_QUERY % (l,n) for l in league for n in range(page_number_limit) ]:
result = result + get_players(url)
for i in league:
for j in range(0, 100):
url = BASE_URL + PLAYER_LIST_QUERY % (l,n)
## send request to url and do scraping
obj = soup.find("xx","cc")
for dd in soup.select('.searchResult tr') if dd.contents[1].name != 'th'


dict([(k,v[0]) for k,v in urlparse.parse_qs(o).items()])
if len(record) != 10:
for i in range(0, 10 - len(record)):
record.append('na')
record.append(unicode(link,'utf-8')) record.append(unicode(query["id"],'utf-8')) record.append(unicode(query["teamid"],'utf-8')) record.append(unicode(query["lega"],'utf-8'))
import csv
def write_csv(filename, content, header = None):
file = open(filename, "wb")
file.write('\xEF\xBB\xBF')
writer = csv.writer(file, delimiter=',')
if header:
writer.writerow(header)
for row in content:
encoderow = [dd.encode('utf8') for dd in row]
writer.writerow(encoderow)
write_csv('players.csv',result,player_fields)


def get_player_match(url):
html = urlopen(url).read()
soup = bs4.BeautifulSoup(html, "lxml")
matches = [ dd for dd in soup.select('.shtdm tr') if dd.contents[1].name != 'th']
records = []
for item in [ dd for dd in matches if len(dd.contents) > 11]: ## filter out the personal part
record = []
for match in [ dd for dd in item.contents if type(dd) is bs4.element.Tag]:
if match.string:
record.append(match.string)
else:
for d in [ dd for dd in match.contents if type(dd) is bs4.element.Tag]:
query = dict([(k,v[0]) for k,v in urlparse.parse_qs(d['href']).items()])
record.append('teamid' in query and query['teamid'] or query['id'])
record.append(d.string and d.string or 'na')
records.append(record)
return records[1:] ##remove the first record as the header
def get_players_match(playerlist, baseurl = BASE_URL + '/player.aspx?'):
result = []
for item in playerlist:
url = baseurl + item[10]
print url
result = result + get_player_match(url)
return result
match_fields = ['date_cn','homeid','homename_cn','matchid','score','awayid','awayname_cn','league_cn','firstteam','playtime','goal','assist','shoot','run','corner','offside','foul','violation','yellowcard','redcard','save']
write_csv('m.csv',get_players_match(result),match_fields)
下一步做什么
探索Javascript异步编程
JavaScript 异步编程简介
回调函数和异步执行
var fn = function(callback) {
// do something here
...
callback.apply(this, para);
};
var mycallback = function(parameter) {
// do someting in customer callback
};
// call the fn with callback as parameter
fn(mycallback);
setTimeout(function(){
console.log("this will be exectued after 1 second!");
},1000);
Javascript线程模型和事件驱动
while(true) {
var event = eventQueue.pop();
if(event && event.handler) {
event.handler.execute(); // execute the callback in Javascript thread
} else {
sleep(); //sleep some time to release the CPU do other stuff
}
}
Javascript异步编程带来的挑战
代码可读性
operation1(function(err, result) {
operation2(function(err, result) {
operation3(function(err, result) {
operation4(function(err, result) {
operation5(function(err, result) {
// do something useful
})
})
})
})
})
流程控制
var urls = ['url1','url2','url3'];
var result = [];
for (var i = 0, len = urls.length(); i < len; i++ ) {
$.ajax({
url: urls[i],
context: document.body,
success: function(){
//do something on success
result.push("one of the request done successfully");
if (result.length === urls.length()) {
//do something when all the request is completed successfully
}
}});
}
异常和错误处理
更好的Javascript异步编程方式
Promise
var promise = doSomethingAync() promise.then(onFulfilled, onRejected)
operation1().then(function (result1) {
return operation2(result1)
}).then(function (result2) {
return operation3(result2);
}).then(function (result3) {
return operation4(result3);
}).then(function (result4) {
return operation5(result4)
}).then(function (result5) {
//And so on
});
var p1 = async1();
var p2 = async2();
var p3 = async3();
Promise.all([p1,p2,p3]).then(function(){
// do something when all three asychronized operation finished
});
doA()
.then(doB)
.then(null,function(error){
// error handling here
})
如果你有选择困难综合症,面对这么多的开源库不知道如何决断,先不要急,这还只是一部分,还有一些库没有或者不完全采用Promise的概念
Non-Promise
Non-3rd Party
eventbus.on("init", function(){
operationA(function(err,result){
eventbus.dispatch("ACompleted");
});
});
eventbus.on("ACompleted", function(){
operationB(function(err,result){
eventbus.dispatch("BCompleted");
});
});
eventbus.on("BCompleted", function(){
operationC(function(err,result){
eventbus.dispatch("CCompleted");
});
});
eventbus.on("CCompleted", function(){
// do something when all operation completed
});
下一代Javscript对异步编程的增强
ECMAScript6
co、Thunk、Koa
var co = require('co');
var fs = require('fs');
var stat = function(path) {
return function(cb){
fs.stat(path,cb);
}
};
var readFile = function(filename) {
return function(cb){
fs.readFile(filename,cb);
}
};
co(function *() {
var stat = yield stat('./README.md');
var content = yield readFile('./README.md');
})();
var thunkify = require('thunkify');
var co = require('co');
var fs = require('fs');
var stat = thunkify(fs.stat);
var readFile = thunkify(fs.readFile);
co(function *() {
var stat = yield stat('./README.md');
var content = yield readFile('./README.md');
})();
co(function *() {
var a = yield request(a);
var b = yield request(b);
})();
co(function *() {
var res = yield [request(a), request(b)];
})();
总结
Python 与 Javascript 之比较
2014年5月13日星期二
最近由于工作的需要开始开发一些Python的东西,由于之前一直在使用Javascript,所以会不自觉的使用一些Javascript的概念,语法什么的,经常掉到坑里。我觉得对于从Javascript转到Python,有必要总结一下它们之间的差异。
基本概念
Python和Javascript都是脚本语言,所以它们有很多共同的特性,都需要解释器来运行,都是动态类型,都支持自动内存管理,都可以调用eval()来执行脚本等等脚本语言所共有的特性。
然而它们也有很大的区别,Javascript这设计之初是一种客户端的脚本语言,主要应用于浏览器,它的语法主要借鉴了C,而Python由于其“优雅”,“明确”,“简单”的设计而广受欢迎,被应用于教育,科学计算,web开发等不同的场景中。
编程范式
Python和Javascript都支持多种不同的编程范式,在面向对象的编程上面,它们有很大的区别。Javascript的面向对象是基于原型(prototype)的, 对象的继承是由原型(也是对象)创建出来的,由原型对象创建出来的对象继承了原型链上的方法。而Python则是中规中矩的基于类(class)的继承,并天然的支持多态(polymophine)。
OO in Pyhton
class Employee:
'Common base class for all employees'
empCount = 0 ##类成员
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
## 创建实例
ea = Employee("a",1000)
eb = Employee("b",2000)
OO in Javascript
var empCount = 0;
//构造函数
function Employee(name, salary){
this.name = name;
this.salary = salary;
this.empCount += 1;
}
Employee.prototype.displayCount = function(){
console.log("Total Employee " + empCount );
}
Employee.prototype.displayEmployee = function(){
console.log("Name " + this.name + ", Salary " + this.salary );
}
//创建实例
var ea = new Employee("a",1000);
var eb = new Employee("b",2000);
因为是基于对象的继承,在Javascript中,我们没有办法使用类成员empCount,只好声明了一个全局变量,当然实际开发中我们会用更合适的scope。注意Javascript创建对象需要使用new关键字,而Python不需要。
除了原生的基于原型的继承,还有很多利用闭包或者原型来模拟类继承的Javascript OO工具,因为不是语言本身的属性,我们就不讨论了。
线程模型
在Javascript的世界中是没有多线程的概念的,并发使用过使用事件驱动的方式来进行的, 所有的JavaScript程序都运行在一个线程中。在HTML5中引入web worker可以并发的处理任务,但没有改变Javascript单线程的限制。
Python通过thread包支持多线程。
不可改变类型 (immutable type)
在Python中,有的数据类型是不可改变的,也就意味着这种类型的数据不能被修改,所有的修改都会返回新的对象。而在Javascript中所有的数据类型都是可以改变的。Python引入不可改变类型我认为是为了支持线程安全,而因为Javascript是单线程模型,所以没有必要引入不可改变类型。
当然在Javascript可以定义一个对象的属性为只读。
var obj = {};Object.defineProperty(obj, "prop", {
value: "test",
writable: false});
在ECMAScript5的支持中,也可以调用Object的freeze方法来是对象变得不可修改。
Object.freeze(obj)
数据类型
Javascript的数据类型比较简单,有object、string、boolean、number、null和undefined,总共六种
Python中一切均为对象,像module、function、class等等都是。
Python有五个内置的简单数据类型bool、int、long、float和complex,另外还有容器类型,代码类型,内部类型等等。
布尔
Javascript有true和false。Python有True和False。它们除了大小写没有什么区别。
字符串
Javascript采用UTF16编码。
Python使用ASCII码。需要调用encode、decode来进行编码转换。使用u作为前缀可以指定字符串使用Unicode编码。
数值
Javascript中所有的数值类型都是实现为64位浮点数。支持NaN(Not a number),正负无穷大(+/-Infiity)。
Python拥有诸多的数值类型,其中的复数类型非常方便,所以在Python在科研和教育领域很受欢迎。这应该也是其中一个原因吧。Python中没有定义NaN,除零操作会引发异常。
列表
Javascript内置了array类型(array也是object)
Python的列表(List)和Javascript的Array比较接近,而元组(Tuple)可以理解为不可改变的列表。
除了求长度在Python中是使用内置方法len外,基本上Javascript和Python都提供了类似的方法来操作列表。Python中对列表下标的操作非常灵活也非常方便,这是Javascript所没有的。例如l[5:-1],l[:6]等等。
字典、哈希表、对象
Javascript中大量的使用{}来创建对象,这些对象和字典没有什么区别,可以使用[]或者.来访问对象的成员。可以动态的添加,修改和删除成员。可以认为对象就是Javascript的字典或者哈希表。对象的key必须是字符串。
Python内置了哈希表(dictS),和Javascript不同的是,dictS可以有各种类型的key值。
空值
Javascript定义了两种空值。 undefined表示变量没有被初始化,null表示变量已经初始化但是值为空。
Python中不存在未初始化的值,如果一个变量值为空,Python使用None来表示。
Javascript中变量的声明和初始化
v1; v2 = null; var v3; var v4 = null; var v5 = 'something';
在如上的代码中v1是全局变量,未初始化,值为undefined;v2是全局变量,初始化为空值;v3为局部未初始化变量,v4是局部初始化为空值的变量;v5是局部已初始化为一个字符处的变量。
Python中变量的声明和初始化
v1 = None v2 = 'someting'
Python中的变量声明和初始化就简单了许多。当在Python中访问一个不存在的变量时,会抛出NameError的异常。当访问对象或者字典的值不存在的时候,会抛出AttributeError或者KeyError。因此判断一个值是否存在在Javascript和Python中需要不一样的方式。
Javascript中检查某变量的存在性:
if (!v ) {
// do something if v does not exist or is null or is false
}
if (v === undefined) {
// do something if v does not initialized
}
注意使用!v来检查v是否初始化是有歧义的因为有许多种情况!v都会返回true
Python中检查某变量的存在性:
try:
v
except NameError
## do something if v does not exist
在Python中也可以通过检查变量是不是存在于局部locals()或者全局globals()来判断是否存在该变量。
类型检查
Javascript可以通过typeof来获得某个变量的类型:
typeof in Javascript 的例子:
typeof 3 // "number"
typeof "abc" // "string"
typeof {} // "object"
typeof true // "boolean"
typeof undefined // "undefined"
typeof function(){} // "function"
typeof [] // "object"
typeof null // "object"
要非常小心的使用typeof,从上面的例子你可以看到,typeof null居然是object。因为javscript的弱类型特性,想要获得更实际的类型,还需要结合使用instanceof,constructor等概念。具体请参考这篇文章
Python提供内置方法type来获得数据的类型。
>>> type([]) is list
True
>>> type({}) is dict
True
>>> type('') is str
True
>>> type(0) is int
True
同时也可以通过isinstance()来判断类的类型
class A:
pass
class B(A):
pass
isinstance(A(), A) # returns True
type(A()) == A # returns True
isinstance(B(), A) # returns True
type(B()) == A # returns False
但是注意Python的class style发生过一次变化,不是每个版本的Python运行上述代码的行为都一样,在old style中,所有的实例的type都是‘instance’,所以用type方法来检查也不是一个好的方法。这一点和Javascript很类似。
自动类型转换
当操作不同类型一起进行运算的时候,Javascript总是尽可能的进行自动的类型转换,这很方便,当然也很容易出错。尤其是在进行数值和字符串操作的时候,一不小心就会出错。我以前经常会计算SVG中的各种数值属性,诸如x,y坐标之类的,当你一不小心把一个字符串加到数值上的时候,Javascript会自动转换出一个数值,往往是NaN,这样SVG就完全画不出来啦,因为自动转化是合法的,找到出错的地方也非常困难。
Python在这一点上就非常的谨慎,一般不会在不同的类型之间做自动的转换。
语法
风格
Python使用缩进来决定逻辑行的结束非常具有创造性,这也许是Python最独特的属性了,当然也有人对此颇具微词,尤其是需要修改重构代码的时候,修改缩进往往会引起不小的麻烦。
Javascript虽然名字里有Java,它的风格也有那么一点像Java,可是它和Java就好比雷峰塔和雷锋一样,真的没有半毛钱的关系。到时语法上和C比较类似。这里必须要提到的是coffeescript作为构建与Javascript之上的一种语言,采用了类似Python的语法风格,也是用缩进来决定逻辑行。
Python风格
def func(list):
for i in range(0,len(list)):
print list[i]
Javascript风格
function funcs(list) {
for(var i=0, len = list.length(); i < len; i++) {
console.log(list[i]);
}
}
从以上的两个代码的例子可以看出,Python确实非常简洁。
作用范围和包管理
Javascript的作用域是由方法function来定义的,也就是说同一个方法内部拥有相同的作用域。这个严重区别与C语言使用{}来定义的作用域。Closure是Javascript最有用的一个特性。
Python的作用域是由module,function,class来定义的。
Python的import可以很好的管理依赖和作用域,而Javascript没有原生的包管理机制,需要借助AMD来异步的加载依赖的js文件,requirejs是一个常用的工具。
赋值逻辑操作符
Javascript使用=赋值,拥有判断相等(==)和全等(===)两种相等的判断。其它的逻辑运算符有&& 和||,和C语言类似。
Python中没有全等,或和与使用的时and 和 or,更接近自然语言。Python中没有三元运算符 A :B ?C,通常的写法是
(A and B) or C
因为这样写有一定的缺陷,也可以写作
B if A else C
Python对赋值操作的一个重要的改进是不允许赋值操作返回赋值的结果,这样做的好处是避免出现在应该使用相等判断的时候错误的使用了赋值操作。因为这两个操作符实在太像了,而且从自然语言上来说它们也没有区别。
++运算符
Python不支持++运算符,没错你再也不需要根据++符号在变量的左右位置来思考到底是先加一再赋值呢还是先赋值再加一。
连续赋值
利用元组(tuple),Python可以一次性的给多个变量赋值
(MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY) = range(7)
函数参数
Python的函数参数支持命名参数和可选参数(提供默认值),使用起来很方便,Javascript不支持可选参数和默认值(可以通过对arguments的解析来支持)
def info(object, spacing=10, collapse=1):
... ...
其它
立即调用函数表达式 (IIFE)
Javascript的一个方便的特性是可以立即调用一个刚刚声明的匿名函数。也有人称之为自调用匿名函数。
下面的代码是一个module模式的例子,使用闭包来保存状态实现良好的封装。这样的代码可以用在无需重用的场合。
var counter = (function(){
var i = 0;
return {
get: function(){
return i;
},
set: function( val ){
i = val;
},
increment: function() {
return ++i;
}
};
}());
Python没有相应的支持。
生成器和迭代器(Generators & Iterator)
在我接触到的Python代码中,大量的使用这样的生成器的模式。
Python生成器的例子
# a generator that yields items instead of returning a list
def firstn(n):
num = 0
while num < n:
yield num
num += 1
sum_of_first_n = sum(firstn(1000000))
Javascript1.7中引入了一些列的新特性,其中就包括生成器和迭代器。然而大部分的浏览器除了Mozilla(Mozilla基本上是在自己玩,下一代的Javascript标准应该是ECMAScript5)都不支持这些特性
Javascript1.7 迭代器和生成器的例子。
function fib() {
var i = 0, j = 1;
while (true) {
yield i;
var t = i;
i = j;
j += t;
}
};
var g = fib();
for (var i = 0; i < 10; i++) {
console.log(g.next());
}
列表(字典、集合)映射表达式 (List、Dict、Set Comprehension)
Python的映射表达式可以非常方便的帮助用户构造列表、字典、集合等内置数据类型。
下面是列表映射表达式使用的例子:
>>> [x + 3 for x in range(4)]
[3, 4, 5, 6]
>>> {x + 3 for x in range(4)}
{3, 4, 5, 6}
>>> {x: x + 3 for x in range(4)}
{0: 3, 1: 4, 2: 5, 3: 6}
Javascript1.7开始也引入了Array Comprehension
var numbers = [1, 2, 3, 4]; var doubled = [i * 2 for (i of numbers)];
Lamda表达式 (Lamda Expression )
Lamda表达式是一种匿名函数,基于著名的λ演算。许多语言诸如C#,Java都提供了对lamda的支持。Pyhton就是其中之一。Javascript没有提供原生的Lamda支持。但是有第三方的Lamda包。
g = lambda x : x*3
装饰器(Decorators)
Decorator是一种设计模式,大部分语言都可以支持这样的模式,Python提供了原生的对该模式的支持,算是一种对程序员的便利把。
Decorator的用法如下。
@classmethod
def foo (arg1, arg2):
....
更多decorator的内容,请参考https://wiki.python.org/moin/PythonDecorators
本人对Javascript和Python的认识有限,欢迎大家提出宝贵意见。
标签: Javascript, Python